Datenschutzkonformes Nutzen von ML-Modellen
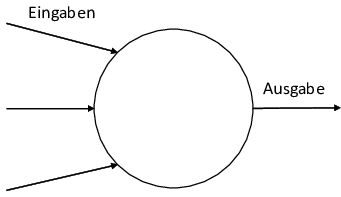 Bild: Mittelstand-Digital Zentrum
Bild: Mittelstand-Digital Zentrum
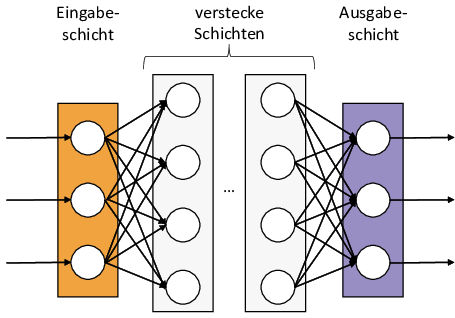 Bild: Mittelstand-Digital Zentrum
Bild: Mittelstand-Digital Zentrum
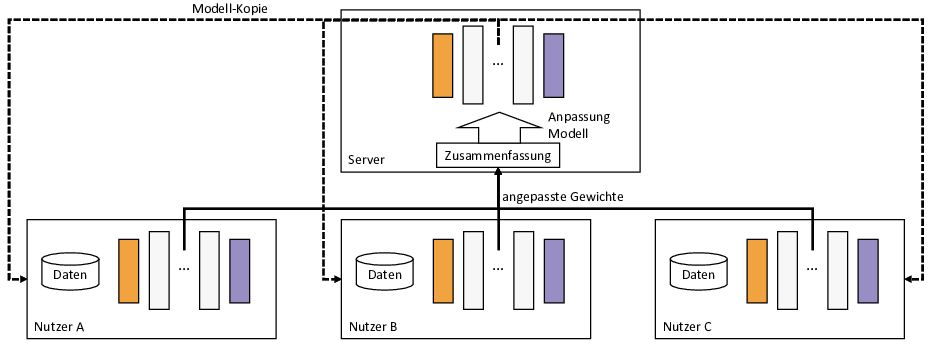 Bild: Mittelstand-Digital Zentrum
Bild: Mittelstand-Digital Zentrum
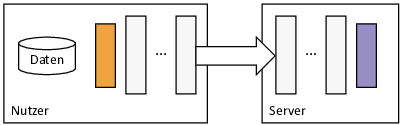 Bild: Mittelstand-Digital Zentrum
Bild: Mittelstand-Digital Zentrum

Maschinelles Lernen zeichnet sich dadurch aus, dass große Datenmengen in kurzer Zeit verarbeitet und in einen neuen Zusammenhang gebracht werden können. Allerdings ist eine solche Datenverarbeitung gesetzlich streng reglementiert. Wie lassen sich also maschinelles Lernen und Datenschutz in Einklang bringen? Der Fachartikel erläutert die Zusammenhänge und zeigt mögliche Lösungswege auf.
Künstliche Intelligenz bzw. konkreter das maschinelle Lernen (kurz ML) ist in aller Munde. Der Erfolg von Diensten wie ChatGPT basiert u. a. auf der Möglichkeit, dass maschinen-gelernte Modelle (kurz ML-Modelle) große Datenmengen verarbeiten und daraus neue Zusammenhänge ermitteln können [1]. Allerdings ist eine solche Datenverarbeitung von personenbezogenen Daten durch die EU-DSGVO seit 2018 reglementiert. Dieser Artikel erläutert anhand von aktuellen Technologien aus Forschung und Praxis, wie beim Erstellen und Nutzen von ML-Modellen datenschutzkonform gearbeitet werden kann, sodass keine Dritten an personenbezogene Daten kommen. Ausgangsbasis für die Betrachtung ist, dass ein ML-Modell personenbezogene bzw. personenbeziehbare Daten (gem. Art. 4 Nr. 1 DSGVO/§46 Nr. 1 BDSG n.F.) [2] lernt und somit diese Daten (gem. Art. 4 Nr. 2 DSGVO/§ 46 Nr. 2 BDSG n.F.) verarbeitet. Solche Daten können bspw. der Name, die Adresse oder das Geschlecht einer Person sein und decken somit alles ab, mit dem eine Person identifiziert werden kann. Zudem wird eine rechtmäßige Verarbeitung (gem. Art. 6 bzw. Art. 9 DSGVO) vorausgesetzt. Würde ein ML-Modell keine personenbezogenen Daten verarbeiten, würde es nicht datenschutzrelevant sein. Dabei gilt aber zu beachten, dass dies vom konkreten Anwendungsfall abhängig sein kann und ggf. andere rechtliche Einschränkungen bspw. das Urheberrecht gelten können.
Wie funktioniert maschinelles Lernen?
Maschinelles Lernen lernt auf Basis typischerweise großer Datenmengen neue Zusammenhänge bzw. Muster. Dazu nutzt ML statistische Modelle, die in einem Trainingsprozess stückweise mittels Trainingsdaten für eine bestimmte Aufgabe verbessert werden. Ein ML-Modell lässt sich bspw. so trainieren, dass es mittels sehr vieler Tierbilder verschiedene Tierarten erkennt. Solch eine Aufgabe wird Klassifikation genannt. In diesem Fall also das Erkennen von verschiedenen Tierklassen.
Moderne ML-Modelle basieren dabei auf einer stark vereinfachten Nachbildung der menschlichen Neuronen im Gehirn. Diese bekommen Eingabedaten auf deren Basis sie aktiviert werden können und im Fall einer Aktivierung Ausgabedaten erzeugen (vgl. Bild 1). Diese Neuronen können dann wie in Bild 2 in Schichten gesammelt werden, die ihrerseits dann aufgereiht werden. Dabei gibt es eine Eingabeschicht, die die Eingabedaten bspw. die Tierbilder entgegennimmt, eine Ausgabeschicht, die das Ergebnis ausgibt, bspw. die erkannte Tierart. Zusätzlich gibt es eine oder mehrere Zwischenschichten, die als „versteckte Schichten“ (engl. „hidden layers“) bezeichnet werden.
Die Neuronen der einen Schicht sind jeweils mit allen Neuronen der jeweils nächsten Schicht (von links nach rechts gesehen) verbunden. Somit werden durch die Aktivierung der Neuronen in der vorherigen Schicht die Eingabedaten für die jeweils folgende Schicht erzeugt. Um jetzt das Aktivierungsverhalten so zu gestalten, dass z. B. bei einem eingegebenen Hundebild auch wirklich die Klasse „Hund“ erkannt wird, müssen dem ML-Modell Trainingsdaten gegeben werden, zu denen die Klasse schon bekannt ist. Dabei wird das Hundebild in die Eingabeschicht gegeben und dann das Ergebnis der Ausgabeschicht mit der bekannten Klasse verglichen. Sollte die Klasse falsch erkannt sein, wird das Aktivierungsverhalten angepasst. Dies erfolgt durch die Anpassung der entsprechenden Gewichte, die an den Übergängen der Neuronen hängen (sog. „gradient descent“). Die Gewichte beschreiben, wie stark der Einfluss der Aktivierung eines Neurons auf das nachfolgende ist. Sind die Gewichte so durch Trainingsdaten angepasst, dass die Ergebnisschicht genügend richtige Entscheidungen trifft, wird von einem trainierten Modell gesprochen. Das trainierte ML-Modell wird i. d. R. nochmal gegen einen unabhängigen Testdatensatz geprüft, um zu vermeiden, dass das Modell nur auf den Trainingsdaten gut funktioniert.
Maßnahmen zum Datenschutz
Dieses Training ist sehr aufwändig und benötigt entsprechende Rechnerressourcen, insbesondere wenn sogenannte Deep Learning (dt. „tiefes Lernen“) Modelle verwendet werden, die typischerweise aus sehr vielen versteckten Schichten mit teils sehr vielen Neuronen pro Schicht bestehen. Daher wird das ML-Modell typischerweise an einer zentralen Stelle bspw. auf einem Server eines Rechenzentrums gehalten und trainiert. Das bedeutet aber auch, dass die Eingabedaten, also im genannten Beispiel die Tierbilder, an diese zentrale Stelle geschickt werden müssen. Das kann dann kritisch werden, wenn diese Daten datenschutzrechtlich relevant sind.
Eine erste wichtige Maßnahme bei der Übertragung von Daten ist, dass diese Übertragung verschlüsselt stattfindet. Zudem sollten Betreiber die Daten vor Zugriff Dritter schützen. Zusätzlich ist es sinnvoll, die Trainingsdaten nach dem Training zu löschen, damit jene nicht mehr im Klartext auf dem Server vorliegen.
Leider genügt das Löschen nur bedingt, da die aktuelle Forschung zeigt, dass durch spezielle Angriffsszenarien die Trainingsdaten aus einem trainierten ML-Modell wiederhergestellt werden können (sog. „Model Inversion Attacks“ [3,4,5]). Um dem entgegenzuwirken wird versucht entweder beim Training gezielte Störungen bei der Anpassung der Gewichte einzubauen (sog. „noisy stochastic gradient descent“) oder die Ergebnisse von vielen parallel trainierten ML-Modellen in einem neuen Modell zu vermischen, sodass aus diesem die Daten nicht reproduziert werden können (sog. „private aggregation of teacher ensembles“, kurz PATE) [3,6].
Eine weitere Idee ist, die Daten vor der Übertragung an den Server zu anonymisieren. Diese Variante wird aber von Experten kritisch gesehen [7,8]. Zum einen lernt das ML-Modell dann nur auf anonymisierten Daten und funktioniert nur noch bedingt genau. Bspw. würde eine Gesichtserkennung, die mit verschwommenen Gesichtsbildern trainiert wurde, schlechter Bilder mit klaren Gesichtern erkennen. Zum anderen zeigte sich, dass anonymisierte Daten sich häufig durch zusätzliche Informationen aus anderen Quellen wieder zu Klardaten umwandeln lassen. Bspw. könnte eine Person auf Basis ihrer Kleidung von einem Bild aus den sozialen Medien wiedererkannt werden.
Eine Lösung besteht in einer besonderen Art der Verschlüsselung, der sog. homomorphen Verschlüsselung [3]. Vereinfacht gesagt erlaubt diese die Berechnung auf verschlüsselten Daten ohne die Daten selbst zu entschlüsseln. Somit könnte ein ML-Modell vorher verschlüsselte Daten erhalten und durch das Training das gewünschte Ergebnis errechnen, ohne jemals die klaren Trainingsdaten zu sehen. Leider funktioniert die homomorphe Verschlüsselung aktuell noch auf sehr einfachen Modellen und ist somit nur für spezielle Aufgaben einsetzbar.
Eine weitere Variante basiert auf dem Einsatz sog. generativer ML-Modelle [3,9]. Diese lernen bspw. wie Bilder von Tieren aussehen und erzeugen dann neue fiktive Tierbilder. So könnte man zunächst die Klardaten nutzen, um solch ein generatives Modell zu trainieren. Dann erzeugt dieses Modell eine Menge von fiktiven neuen Trainingsdaten für das eigentliche ML-Modell. Nach dem Training mit den fiktiven Daten können schließlich die Klardaten und das generative Modell gelöscht werden. Das Reproduzieren der Trainingsdaten würde so maximal die fiktiven Daten zu Tage tragen.
Es gibt auch Bestrebungen, dass die Trainingsdaten nicht mehr das Gerät des Nutzers verlassen müssen. Eine Variante, die u. a. Google für das Generieren von intelligenten Antworten nutzt [10], ist das föderale Lernen [7]. Die Idee besteht darin ein vortrainiertes ML-Modell auf die Endgeräte bspw. das Smartphone von Nutzern zu übertragen und dort mit den lokal vorhandenen Daten zu trainieren (vgl. Bild 3). Nach dem lokalen Training werden an den Server nur die Änderung am ML-Modell, d. h. die Änderungen in den Gewichten an den Server übertragen. Diese werden dann mit den Änderungen anderer Nutzer vermischt, sodass möglichst keine Rückschlüsse auf Einzelne aus den Änderungen möglich ist, und das zentrale ML-Modell wird angepasst. Ein Nachteil besteht darin, dass die Endgeräte das gesamte ML-Modell trainieren müssen, wozu üblicherweise das Smartphone gerade nicht in Benutzung sein sollte, um die entsprechenden Rechenressourcen zu nutzen.
Eine andere Variante basiert darauf das ML-Modell zwischen zwei versteckten Schichten zu zerteilen (vgl. Bild 4). Experten sprechen dabei vom sog. Split-Learning (dt. zerteiltes Lernen) [11]. Die Idee ist, dass auf dem Endgerät die Nutzerdaten in den ersten Schichten verarbeitet werden und dann ab einer speziellen Trennschicht die Aktivierungsinformationen an einen Server übertragen werden und dort weitertrainiert wird. Die Anpassung der Gewichte erfolgt analog entgegengesetzt, d. h. vom Server auf das Endgerät. Dabei ist die Trennschicht so konstruiert, dass mit den übertragenden Informationen nicht auf die Ursprungsdaten geschlossen werden kann, aber trotzdem die gewünschte Ausgabe trainiert werden kann [12]. So ist es schwieriger die Original-Tierbilder zu rekonstruieren, aber es kann immer noch korrekt die Tierart erkannt werden. In der Regel braucht das Training in diesem Fall aber länger, um eine ähnliche Genauigkeit zu erreichen wie zentral trainierte Modelle. Es gibt also einen bunten Blumenstrauß an Techniken, damit ML auch auf sensiblen Daten verwendet werden kann, ohne dass der Datenschutz verletzt wird. Wie bei allen ML-Modellen gibt es nicht das beste Modell (sog. „No-Free-Lunch-Theorem“ [13]), und bestimmte Techniken funktionieren für gewisse Anwendungsfälle besser bzw. schlechter. Auch wenn einige Techniken noch in der Forschung sind, ist aufgrund der gesetzlichen Bestimmungen gepaart mit dem Nutzen des maschinellen Lernens davon auszugehen, dass sich diese oder ähnliche Techniken in der Praxis etablieren werden.
Hinweis: Alle in diesem Beitrag dargestellten Informationen entsprechen keiner Rechtsberatung bzw. ersetzen keine rechtliche Beratung. Sie stellen lediglich die persönliche Wahrnehmung des Autors dar. Der Autor übernimmt keine Haftung für eventuelle Folgeschäden, insbesondere rechtlicher Natur, die aus fehlerhaften Handlungen, die aus diesem Beitrag herrühren, entstehen.
Literaturverzeichnis zum Artikel
Das Literaturverzeichnis finden Sie online auf COMPUTER SPEZIAL unter dem Link www.t1p.de/CS-2-2023-LitML sowie dem angehängten QR-Code.